Discussions of the use of surrogate keys versus natural keys rarely address the full range of data integrity errors that can occur when surrogate keys are used. This post illustrates how surrogate keys can lead to loss of data integrity in a way that is apparently not widely recognized.
There is one well-known type of data integrity error that can occur with surrogate keys. That is, when a table with a surrogate key also has a column (or combination of columns) that make up a natural key, duplicate data can be entered--and entity integrity therefore violated. This potential problem can be easily avoided, however, by creating a unique index on the columns making up the natural key.
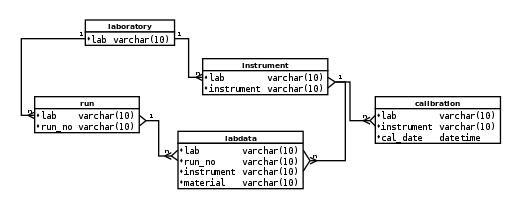
The other, and less widely recognized, problem can lead to loss of relational integrity between tables. This problem can be illustrated using the data structure shown in Figure 1. This data structure represents a series of measurements made by a single organization (laboratory) using multiple instruments, as might be done when testing materials or procedures under a variety of different circumstances. Figure 1 shows the model data structure, which is the most direct representation of real-world data and relationships, using natural keys as primary keys. Only the primary key columns of each table are shown in the figure; in practice these tables would have additional attribute columns.
The DDL that would create this data structure is shown in Listing 1. Figure 1 and Listing 1 are provided primarily for reference, and for contrast with the approach to implementing this data model using surrogate keys.
There is one well-known type of data integrity error that can occur with surrogate keys. That is, when a table with a surrogate key also has a column (or combination of columns) that make up a natural key, duplicate data can be entered--and entity integrity therefore violated. This potential problem can be easily avoided, however, by creating a unique index on the columns making up the natural key.
The other, and less widely recognized, problem can lead to loss of relational integrity between tables. This problem can be illustrated using the data structure shown in Figure 1. This data structure represents a series of measurements made by a single organization (laboratory) using multiple instruments, as might be done when testing materials or procedures under a variety of different circumstances. Figure 1 shows the model data structure, which is the most direct representation of real-world data and relationships, using natural keys as primary keys. Only the primary key columns of each table are shown in the figure; in practice these tables would have additional attribute columns.
The DDL that would create this data structure is shown in Listing 1. Figure 1 and Listing 1 are provided primarily for reference, and for contrast with the approach to implementing this data model using surrogate keys.
Figure 1. Model data structure

Listing 1. DDL for model data structure
create table laboratory ( lab character varying (10) not null primary key ); create table instrument ( lab character varying (10) not null, instrument character varying (10) not null, constraint pk_instrument primary key (lab, instrument), constraint fk_instumentlab foreign key (lab) references laboratory (lab) on update cascade on delete cascade ); create table run ( lab character varying (10) not null, run_no character varying (10) not null, constraint pk_run primary key (lab, run_no) constraint fk_run_lab foreign key (lab) references laboratory (lab) on update cascade on delete cascade ); create table labdata ( lab character varying (10) not null, run_no character varying (10) not null, instrument character varying (10) not null, material character varying (10) not null, constraint pk_labdata primary key (lab, run_no, instrument, material), constraint fk_labdata_run foreign key (lab, run_no) references run (lab, run_no) on update cascade on delete cascade, constraint fk_labdata_instr foreign key (lab, instrument) references instrument (lab, instrument) on update cascade on delete cascade );
The implementation of this model using surrogate keys is shown in Figure 2. Columns making up both the primary (surrogate) key and the candidate (natural) key are shown. Attribute columns, again, are not shown. The calibration table is not shown in Figure 2, as it is not needed for this example.
Figure 2. Model data structure with surrogate keys

DDL to implement this model using surrogate keys is shown in Listing 2. Because surrogate keys are not part of the SQL standard, the implemetation of surrogate keys is DBMS-specific. In this case (Figure 1 and Listing 2), the implementation is specific to SQL Server. SQL Server is used for this example because it cannot cascade updates and deletions through multiple pathways, and surrogate keys can eliminate the need for cascading updates. Thus, a SQL Server implementation of the model data structure is particularly likely to make use of surrogate keys. Three notable features of this DDL are:
- Each table has a unique index on the natural key to prevent data integrity errors resulting from creation of duplicate rows with the same natural key.
- There is no specification that updates be cascaded, in the expectation that the use of surrogate keys makes this unnecessary.
- All deletions are cascaded using triggers instead of "on delete cascade" clauses. SQL Server cannot cascade deletions to the labdata table, so one at least of those cascading deletions has to be handled by a trigger. In that case, however, SQL Server also cannot automatically cascade deletions from the laboratory table to the child table because SQL Server does not support "before delete" triggers, and the "instead of delete" trigger that must be used prevents SQL Server from guaranteeing that the automatic cascading deletion from the laboratory table is completed successfully. Consequently, all deletions are cascaded using triggers.
Listing 2. DDL for model data structure with surrogate keys
create table laboratory ( lab_id integer identity(1,1) not null primary key, lab character varying (10) not null ); create unique index ix_nk_lab on laboratory (lab); GO create table instrument ( instrument_id integer identity(1,1) not null primary key, lab_id integer not null, instrument character varying (10) not null, constraint fk_instrlab foreign key (lab_id) references laboratory (lab_id) ); create unique index ix_nk_instrument on instrument (instrument); GO create table run ( run_id integer identity(1,1) not null primary key, lab_id integer not null, run_no character varying (10) not null, constraint fk_runlab foreign key (lab_id) references laboratory (lab_id) ); create unique index ix_nk_run on run (lab_id, run_no); GO create trigger tr_lab_del on laboratory instead of delete as begin delete from instrument where lab_id in (select lab_id from Deleted); delete from run where lab_id in (select lab_id from Deleted); delete from laboratory where lab_id in (select lab_id from Deleted); end; GO create table labdata ( labdata_id integer identity(1,1) not null primary key, run_id integer not null, instrument_id integer not null, material character varying (10) not null, constraint fk_labdatarun foreign key (run_id) references run (run_id) on delete cascade, constraint fk_labdatainst foreign key (instrument_id) references instrument (instrument_id) ); create unique index ix_nk_labdata on labdata (run_id, instrument_id, material); GO create trigger tr_instr_del on instrument instead of delete as begin delete from labdata where instrument_id in (select instrument_id from Deleted); delete from instrument where instrument_id in (select instrument_id from Deleted); end; create trigger tr_run_del on run instead of delete as begin delete from labdata where run_id in (select run_id from Deleted); delete from run where run_id in (select run_id from Deleted); end;
Listing 3 contains DML to insert several rows into the laboratory, instrument, and run tables of the structure shown in Figure 2.
Listing 3. Load lab, instrument, and run data
insert into laboratory (lab) values ('LabA');
insert into laboratory (lab) values ('LabB');
insert into instrument (lab_id, instrument) values (
(select lab_id from laboratory where lab='LabA'),
'Instr1');
insert into run (lab_id, run_no) values (
(select lab_id from laboratory where lab='LabB'),
'Run001');
At this point the data tables have been created using surrogate keys, and valid data have been added to three of the tables. Data can now be added to the labdata table. Adding data to that table will illustrate how surrogate keys allow the introduction of data integrity errors.
Listing 4 shows the addition of a row to the labdata table. This insert statement should fail, because the row that is added references a run conducted by laboratory B, using an instrument at laboratory A. The insert statement succeeds, however, introducing invalid data into the labdata table. Such a statement would fail if natural keys were used for these tables. The statement succeeds, and introduces invalid data, because surrogate keys have been used.
Listing 4. Insert lab data
Listing 4 shows the addition of a row to the labdata table. This insert statement should fail, because the row that is added references a run conducted by laboratory B, using an instrument at laboratory A. The insert statement succeeds, however, introducing invalid data into the labdata table. Such a statement would fail if natural keys were used for these tables. The statement succeeds, and introduces invalid data, because surrogate keys have been used.
Listing 4. Insert lab data
insert into labdata (run_id, instrument_id, material) values ( (select run_id from run where lab_id=(select lab_id from laboratory where lab='LabB') and run_no='Run001'), (select instrument_id from instrument where lab_id=(select lab_id from laboratory where lab='LabA') and instrument='Instr1'), 'MaterialX' );
To alleviate this problem, a trigger needs to be created for the labdata table which, for insert or update, will compare the corresponding lab_id values in the instrument and run tables, and cancel the insert or update statement if the lab_id values do not match. In this case the trigger only needs to look back one level. In other data models the trigger may need to look back through multiple levels of tables to check the data.
However, addition of such a trigger on the labdata table does not eliminate all the ways in which data integrity errors can be introduced. Data integrity errors can also be introduced via update statements to the instrument and run tables. Listing 5 shows an update to values in the run table that will introduce data integrity errors into the labdata table despite the new trigger on the labdata table. Updates to the instrument table can have the same effect.
Listing 5. Update data
insert into laboratory (lab) values ('LabC');
update run
set lab_id=(select lab_id from laboratory where lab='LabC')
where
lab_id=(select lab_id from laboratory where lab='LabB')
and run_no='Run001';
The problem of update statements introducing data integrity errors can also be addressed by adding triggers. Conceptually, in this case a trigger should be defined for the run table (and also for the instrument table) that looks into the labresult table to check that conflicting data are not created. For this data model, assuming that there are not already invalid data in the labdata table, an update like that shown in Listing 5 would always create a conflict within the affected row of the labresult table, and therefore introduce invalid data. Therefore, as a practical matter, the trigger on the run table (and also on the instrument table) should simply prevent updates like that shown in Listing 5.
Updates like that shown in Listing 5 do not need to be prevented if natural keys are used. If natural keys are used, the update would fail if Lab C is not also referenced in the instrument table, but it would succeed if the instrument table contains compatible data.
This example illustrates that the use of surrogate keys with certain types of data models potentially allows the introduction of data integrity errors, and that the problem a) requires the creation of additional triggers for insert and update operations, and b) may prevent the execution of legitimate update operations.
Updates like that shown in Listing 5 do not need to be prevented if natural keys are used. If natural keys are used, the update would fail if Lab C is not also referenced in the instrument table, but it would succeed if the instrument table contains compatible data.
This example illustrates that the use of surrogate keys with certain types of data models potentially allows the introduction of data integrity errors, and that the problem a) requires the creation of additional triggers for insert and update operations, and b) may prevent the execution of legitimate update operations.